유통데이터분석 공모전을 진행하던 중, 시계열 분석과 회귀분석의 차이를 명확히 할 필요가 있다고 판단하였다.
그래서 오늘은 각각의 특징이나 대표적 기법들을 다루고, 이 두 가지 상황을 동시에 적용해야 할 때 적합한 모델/분석기법에 대해서 알아보려고 한다.
1. 시계열 분석
- 특징: 시간에 따른 데이터의 흐름을 분석하고 미래 값을 예측하는 데 중점을 둔다. 자기상관성(autocorrelation), 추세(trend), 계절성(seasonality), 주기성(cycle), 변동성(volatility) 등을 고려한다는 특징이 있다.
- 대표적 기법:
- AR (AutoRegression): 과거 자신의 값들을 이용해 현재 값을 예측.
- MA (Moving Average): 과거의 예측 오차를 이용해 현재 값을 예측
- ARIMA (AutoRegressive Integrated Moving Average): 과거의 값과 오차를 이용하여 미래를 예측.
- SARIMA: ARIMA에서 계절성을 고려한 분석 기법.
- LSTM (Long Short-Term Memory): 딥러닝 기반의 시계열 예측 기법으로, 장기 의존성을 모델링함.
2. 회귀분석
- 특징: 종속변수와 독립변수 간의 관계를 분석하여 예측하는 모델. 시간 의존성은 고려하지 않으며, 독립변수들이 종속변수에 미치는 영향을 분석하는 것이 목적.
- 주요 개념: 변수 간 상관관계, 독립변수와 종속변수 간의 회귀계수 추정.
- 대표적 기법:
- 단순 회귀분석: 하나의 독립변수를 사용해 종속변수를 예측.
- 다중 회귀분석: 여러 개의 독립변수를 사용해 종속변수를 예측.
즉, 시계열 분석은 t시점을 기준으로 이전시점(t-1, t-2 ...)을 기반으로 예측을 진행하는 것이고,
회귀분석은 종속변수에 영향을 주는 독립변수들을 분석하는 것이다.
즉, 시계열 분석에서의 독립변수는 이전 시점(t-1, t-2...)이고, 종속변수는 현재시점(t)라고 생각하면 이해하기에 쉬울 것이다.
3. 두 분석 기법을 동시에 적용하는 방법
그렇다면 여러 독립변수에 대한 종속변수를 시점별로 예측해야 하는 상황에서는 어떤 분석 기법을 사용해야 할까?
시계열 분석과 회귀분석을 함께 사용할 수 있는 모델이 있다면 시계열 데이터의 시간적 흐름을 고려하면서도, 여러 독립변수의 영향을 반영할 수 있을 것이다. 이 방법이 바로 다중 시계열 회귀 모델이다.
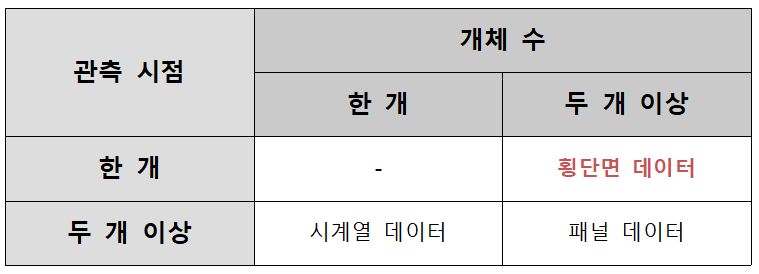
1) Autoregressive Distributed Lag (ARDL) 모델
이 모델은 시계열 데이터에서 시점별로 독립변수와 종속변수 간의 관계를 분석하는 회귀모델이다. 특정 시점의 독립변수와 이전 시점의 종속변수가 현재 종속변수에 미치는 영향을 분석한다.
Autoregressive Distributed Lag (ARDL) 모델은 시계열 데이터 분석에서 사용되는 회귀 모델로, 종속 변수의 과거 값(AR: Autoregressive)과 독립 변수들의 현재 및 과거 값(Lag)을 이용하여 종속 변수를 설명하는 모델이다.
이 모델은 시계열 변수들 간의 단기 및 장기 관계를 동시에 분석할 수 있어, 특히 공적분 관계(long-run equilibrium)를 분석할 때 유용하다는 특징을 갖는다.
식의 형태는 다음과 같다:

이 모델은 시계열 데이터의 과거 값(종속 변수와 독립 변수 모두)을 이용해 현재의 종속 변수를 설명하는 모델로,
단기 및 장기 관계를 동시에 분석할 수 있는 강력한 도구로 사용된다.
ARDL 모델과 관련된 구체적인 설명은 아래 기술블로그 사이트를 참고하길 바란다.
https://nyamin9-data.tistory.com/109
2) LSTM 기반 다중 회귀
다음으로는 '시계열 딥러닝 기반 모델'하면 대부분이 떠올리는 LSTM 모델이다.
딥러닝 기반의 LSTM은 시계열 데이터의 장기 의존성을 반영하는 데 유용하다. 동시에 여러 독립변수를 입력으로 받아, 종속변수를 예측할 수 있다. LSTM과 관련해서는 이전 게시글에서 자세히 다뤘기 때문에 간단하게 설명하고 넘어가도록 하겠다.
- 입력: 독립변수 (여러 개의 피처: 각 시점별 코로나 데이터, 계절 데이터 등)
- 출력: 시계열 종속변수 예측
LSTM 구조를 다중 회귀 문제에 적용할 수 있다. 기본적으로 각 시점에서 여러 독립변수를 입력으로 받아서, 다음 시점의 종속변수를 예측하게 된다.
모델 구조의 기본 형태:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(n_steps, n_features)))
model.add(Dense(1)) # 종속변수 1개 예측
model.compile(optimizer='adam', loss='mse')
# 데이터 훈련
model.fit(X, y, epochs=200, verbose=0)이러한 방법으로 두 분석을 동시에 수행할 수 있으며, 데이터의 특성과 목적에 맞춰 모델을 선택하고 적용할 수 있다.