네 번째 TASK - MongoDB에서 유사 데이터 join
01. TASK 요약
지팬스 스마트로에서 진행하고 있는 주요 사업 중 하나는 해양수산 빅데이터를 판매하는 것이다.
현재 선박 관련 데이터는 실시간으로 MongoDB에 들어오고 있는데,
소비자가 MongoDB에 저장되어있는 데이터를 구매했을 때
(추가 구매를 하도록) 유사한 다른 데이터와 join해서 제공할 수 있도록 하는 것이 이번 업무이다.
여기서 가장 큰 문제!
MongoDB는 Mysql이 아니라 NoSQL이고,
이는 관계형데이터베이스가 아니기에 DB 내부에서는 join이 불가능하다는 점이다.
정리하자면, 관계형 데이터베이스(RDB)에 해당하지 않는 몽고디비에 저장된 데이터를
어떻게 join해서 csv파일로 저장하는 것이 가장 효율적인 방식인가에 대한 고민 이번 업무의 근본적인 문제이다.
이를 통해 소비자들의 추가 구매를 유발하고 보다 체계적인 데이터의 관리를 할 수 있을 것이다.
02. 생각해 봐야 할 Points
✅ 연관성이 있는 테이블을 어떻게 찾을 것인가?
✅ 동일한 칼럼을 어떻게 찾을 것인가?
✅ 칼럼명의 변수(띄어쓰기, 표현방식 차이, 오타 등)들은 어떻게 제거할 것인가?
✅ 저장된 데이터에 존재하는 결측치, 표현 방식의 차이는 어떻게 처리할 것인가?
✅ 유실데이터가 많은 경우?
위와 같은 다양한 고민 끝에 필자가 제시한 업무 진행 방식은 아래와 같다.
03. 업무 진행 방식
1. dbdiagram.io 사이트 활용해서 ERD 제작 → 연관성 높은 key값(칼럼) 파악
2. 연관성 높은 두 칼럼의 유사도 분석.
+ 결측치 비율, 일치율도 함께 분석하면 보다 의미있는 분석이 될 듯.
3. 해당 칼럼으로 join이 가능하다는 결론이 나오면 파이썬에서 Inner Join 진행
위와 같은 단계로 업무를 수행하기 위해서는
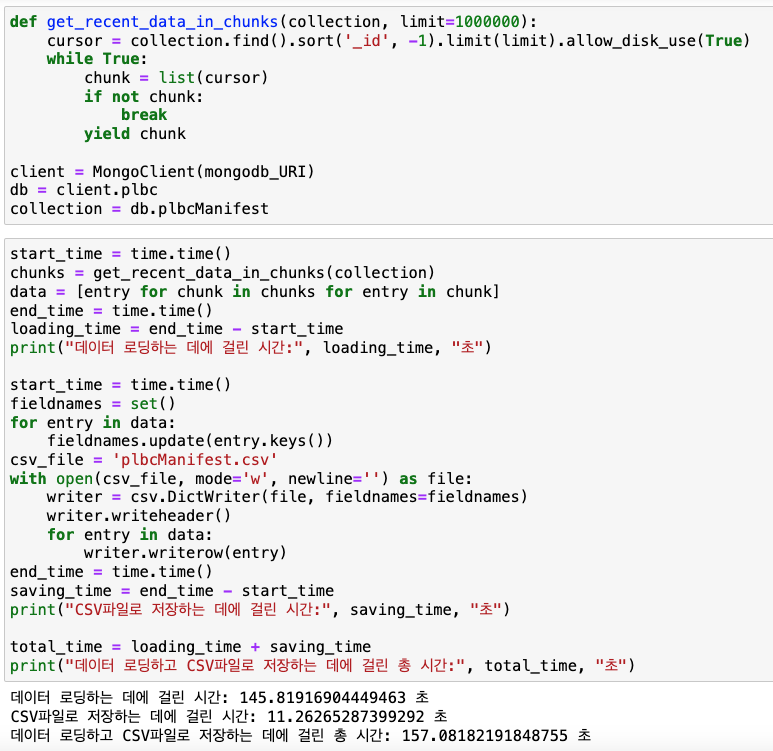
데이터 로딩하는 데에 걸리는 시간을 사전에 체크해야 한다.
04. 사전작업 - 데이터 로딩 시간 측정
사전작업 결과는 아래와 같다.
1) 컬렉션에 저장된 key의 개수 (칼럼개수)나 데이터의 크기에 따라서 데이터 로딩시간은 천차만별
- db.plbcContainerIoResult
데이터 로딩: 56.2초
CSV 저장: 4.4초
total: 60.6초

- db.plbcManifest
데이터 로딩: 145.8초
CSV 저장: 11.3초
total: 157.1초
2) Excel파일 저장도 시도해보았으나, CSV 파일 저장방식에 비해 비효율적으로 보임.
- db.plbcManifest (이전에 시도해보았던 데이터 중 로딩 시간이 비교적 오래 걸렸던 콜렉션으로 실험)
데이터 로딩 : 143.1초
>> (네트워크 연결 상태에 따라 약간의 차이가 있어보임.)
CSV 저장 : 11.3초
Excel 저장 : 605.9초

05. 추가로 고민해볼 Points
- 표현 방식에 대한 고민해볼 것. (참고 사이트, 디자인, 기획분야도 고민해볼 것.)
- 구현 가능한 선에서의 재현. 일단은 해당 페이지에 대한 아이디어 고민을 해보자!
- 주 타겟층: 부산대학교 교수님 (연구용도)
- 개인 llm 언어모델 개발? 지피터처럼 사용하되 정보가 나가지 않도록.
- 쌓여있는 데이터를 어떻게 활용할 것인가? → 판매가 최선일까?
'슬기로운 인턴생활' 카테고리의 다른 글
| [슬기로운 인턴생활2] 칼만필터Kalman Filter의 개념, 기본원리, 구성요소, 수식, 코드 예제 알아보기 (2) | 2024.10.07 |
|---|---|
| [슬기로운 인턴생활2] smart factory스마트팩토리 / SCADA / PLC / HMI 알아보기 (0) | 2024.08.20 |
| [슬기로운 인턴생활2] J-System(제이시스템)의 task (0) | 2024.08.19 |
| [슬기로운 인턴생활2] Intouch 기본 개념 / Tag, Script 예제 (0) | 2024.08.19 |
| [슬기로운 인턴생활] 세 번째 Task - DB에서 불러온 데이터로 TAT 고도화 (0) | 2024.03.04 |



