01. OCR이란?
OCR(광학 문자 인식)은 Optical Character Recognition의 약자로,
스캔한 종이 문서나 PDF 파일, 텍스트 이미지 등 다양한 종류의 문서를
편집/검색 가능한 데이터로 변환하는 데에 사용되는 기술이다.

딥러닝을 적용한 OCR은 글자의 영역을 탐지하는 모델(Text Detection Model)과
해당 영역에서 글자를 인식하는 모델(Text Recognition Model) 두 가지 단계로 구성되어 이다.
OCR의 과정을 두 단계로 나누는 이유는
데이터를 다양하게 활용하여 원활한 학습이 가능하고, 자원의 효율성과 언어별 정확도 등을 향상시킬 수 있기 때문이다.
그럼 이제 본격적으로 OCR 사용방법에 대해 공부해보자.
02. API의 개념과 활용
OCR을 제대로 활용하기 위해서는 우선 API에 대해 잘 알고있어야 한다.
API(Application Programming Interface)는 응용 프로그램 프로그래밍 인터페이스로,
쉽게 말해 어떤 서버의 특정 부분에 접속해서
그 안에 있는 데이터와 서비스를 이용할 수 있도록 해주는 소프트웨어 도구이다.
만약 OCR의 기능을 사용해야할 때,
해당 기능을 처음부터 구축하고 개발하는 것은 정말 많은 시간이 소비될 것이다.
따라서 우리는 OCR 기술 구축을 이미 완료한 회사에서 제공하는
OCR API를 사용함으로써 아주 간단하게 해당 기능을 가져와 사용할 수 있다.
다시 말해 OCR API는 도구를 직접 만들지 않고도 이미지에서 텍스트를 읽을 수 있는 도구를 빌려오는 것과 같다.
아래 링크는 네이버 클라우드 플랫폼 사이트에서 제공하는
CLOVA의 Text OCR API 호출 방법이다. 구체적으로 잘 설명되어 있으니 참고 바란다.
https://guide.ncloud-docs.com/docs/clovaocr-example01
Text OCR API 호출
guide.ncloud-docs.com
03. OCR Pre-trained 모델 적용
필자는 '초등학생의 받아쓰기 채점 자동화'를 목적으로 네이버 클로바 API를 활용해보려고 하였으나,
생각보다 그 결과가 좋지 않았다.
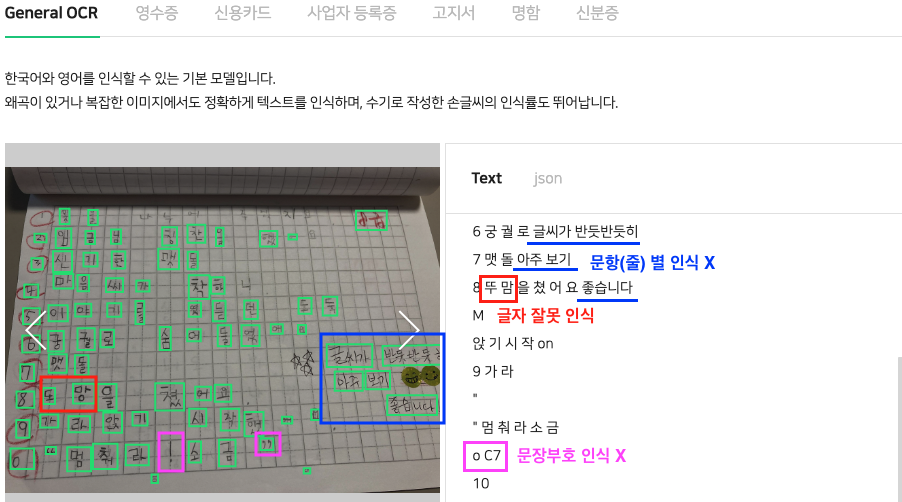
위와 같은 문제 세 가지는 받아쓰기 채점에 있어서 치명적이기 때문에
네이버 CLOVA API를 사용하기보다는 Pre-trained 모델을 사용해서 진행해보는 것이 더 정확도가 높을 것이라 판단했다.
첫 번째 시도는
22년도 12월부터 23년 2월까지 총 세 달간 데이콘에서 진행된 OCR 공모전에 참여한 사람 중,
TROCR 모델을 학습시킨 참가자의 코드를 참고하여 받아쓰기 이미지를 텍스트로 변환해보고자 한 것이다.
대회 개요는 아래와 같다.

참고 깃허브: https://github.com/baesunny/Korean-OCR-Model-Design-based-on-Keras-CNN
참고 블로그: https://mz-moonzoo.tistory.com/13
데이콘 대회 정보 및 학습/테스트 데이터 출처: https://dacon.io/competitions/official/236042/talkboard
Vision Encoder Decoder Models: https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder
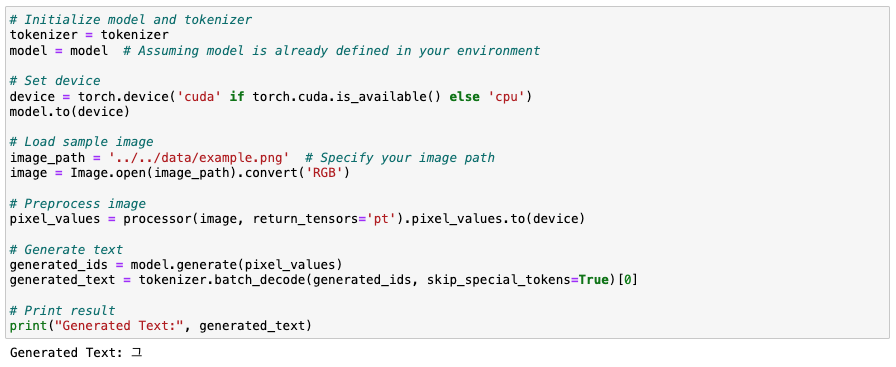
위의 깃허브 링크에 있는 모델(trocr) 사용해서 학습시킨 후에 받아쓰기 이미지를 넣어봤는데,
모델 학습에 사용되었던 데이터 7만 개 정도가 주로 짤막한 글자나 단어 위주여서 그런지
받아쓰기 페이지 내에 있는 모든 글자를 제대로 인식하지는 못 했다.
- 학습 데이터 예시 이미지

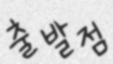
- 단어 위주의 테스트 데이터 출력 결과 예시 → 가끔 오타나 오류가 발생하기는 하지만 대체로 인식은 잘 하는 듯함.

- 모델학습 후 입력한 받아쓰기 이미지

- 받아쓰기 이미지 출력 결과 ( → 문장 자체를 인식하지 못함.)
1차 결론 :
- 단어 위주의 글자 이미지들은 모델이 대부분 제대로 인식하였고, 오류가 발생하는 경우는 대개 '서술어'인 경우였음.
- 문장 자체를 인식하지 못한 것으로 보아, 데이터로 받아쓰기 이미지를 사용하여 fine-tuning해 볼 필요 있을 듯.
- 모델을 Text Detection Model과 Text Recognition Model로 나누어 적용하면 정확도가 높아질 것으로 보임.
첫 번째 시도를 통해 위와 같은 세 가지의 결론을 얻을 수 있었다.
비록 결론이 성공적이지는 않았지만,
이러한 시행착오를 통해 또 다른 방향성을 정해갈 수 있었기에 좋은 경험이었다고 생각한다.
다음 게시글에서는 Pre-trained된 Text Detection Model과Text Recognition Model을
두 개 다 적용해 본 결과를 정리하여 포스팅하도록 하겠다.
'딥러닝' 카테고리의 다른 글
| [딥러닝] 생성형 AI의 개념과 주요 모델 (0) | 2024.07.16 |
|---|---|
| [딥러닝] NLP 분석의 기초 개념과 코드 예제 (0) | 2024.07.08 |
| [딥러닝] RNN 알아보기 (0) | 2024.05.06 |
| [딥러닝] 퍼셉트론(perceptron) / MLP(Multi Layer Perceptron) / 경사하강법 (0) | 2024.02.29 |
| [딥러닝] CNN(Convolutional Neural Network) 기본 구조 (3) | 2024.01.29 |


